5.1. ファイル処理#
5.1.1. データの読み込み#
データを属性ごとにカンマで区切って整形した形式を CSV(comma-separated values)フォーマットと呼びます。また、カンマの代わりにタブ文字で区切った形式は TSV(tab-separated values)フォーマットと呼ばれます。こうした整形済みのファイルを読み込む際には、Pandas モジュールの機能を利用すると便利です。たとえば、CSV ファイルを読み込むには、pd.read_csv 関数にファイルのパスを指定して実行するだけです。
pd.read_csv 関数を使って読み込まれたデータは、データフレーム(DataFrame)と呼ばれる Pandas 独自のデータ型で保存されます。データフレームでは、行と列が明確に区別されており、それぞれが CSV ファイルの行と列に対応しています。データフレーム型に対しては、特定の列や行の抽出、条件に一致する行の抽出、統計量の計算など、さまざまな操作を簡単に行うことができます。
では実際に、どんぐりの重さを記録したデータを読み込んでみましょう。このデータは acorns.clean.csv という名前で保存されており、CSV フォーマットになっています。
# !wget https://py.biopapyrus.jp/data/acorns.clean.csv
x = pd.read_csv('acorns.clean.csv')
何も表示されない場合は、データが正しく読み込まれ、変数 x に代入されたことを意味します。ただし、もし次のようなエラーが表示された場合には、それぞれに応じた対処が必要です。
NameError: name 'pd' is not defined
このエラーは、Pandas モジュールが正しくインポートされていないことが原因です。Pandas をインポートしてから、再度ファイルの読み込みを実行してください。FileNotFoundError: [Errno 2] No such file or directory: 'acorns.csv'
このエラーは、指定されたファイルが見つからないことを意味します。ファイル名やパスが間違っている可能性があります。使用している OS やファイルを保存した場所によっては、コード例にあるような単純なファイル名では読み込めない場合があります。ファイルが存在する正確なパスを確認し、それを指定してください。
なお、オプションを指定せずに読み込むと、ファイルの最初の行はヘッダー行として認識され、その値がデータフレームの列名として自動的に設定されます。もしファイルにヘッダー行が含まれていない場合は、次のように header=None を指定して読み込む必要があります。
# !wget https://py.biopapyrus.jp/data/acorns.clean.nh.csv
x = pd.read_csv('acorns.clean.nh.csv', header=None)
また、ファイル内にデータとは無関係なメタデータやコメント行が含まれている場合は、comment オプションを使って無視することができます。たとえば、# で始まる行をコメントとして無視するには、次のようにします。
# !wget https://py.biopapyrus.jp/data/acorns.clean.meta.csv
x = pd.read_csv('acorns.clean.meta.csv', comment='#')
CSV フォーマットではなく、タブ区切りの TSV フォーマットの場合は sep オプションで区切り文字をタブ(\t)に指定します。
# !wget https://py.biopapyrus.jp/data/acorns.clean.tsv
x = pd.read_csv('acorns.clean.tsv', sep='\t')
このように、pd.read_csv 関数は柔軟なオプションを備えており、さまざまな形式の CSV ファイルを簡単に読み込むことができます。
5.1.2. データの確認#
Pandas で読み込まれたデータを print 関数で出力させると、次のように表示されます。
x = pd.read_csv('acorns.clean.csv')
print(x)
tree weight height diameter
0 kunugi 5.55 2.27 1.89
1 kunugi 4.62 1.98 1.84
2 kunugi 5.05 2.08 1.90
3 kunugi 5.44 2.18 1.91
4 kunugi 5.60 2.20 1.93
5 kunugi 4.83 2.19 1.85
6 kunugi 5.55 2.16 2.00
7 kunugi 5.13 2.20 1.87
8 kunugi 6.03 2.26 2.01
9 kunugi 7.41 2.35 2.12
10 konara 1.60 2.11 1.10
11 konara 1.49 2.04 1.09
12 konara 1.74 2.30 1.17
13 konara 1.57 2.11 1.11
14 konara 1.88 2.33 1.11
15 konara 1.63 2.12 1.14
16 konara 1.45 2.06 1.09
17 konara 1.07 1.91 0.98
18 konara 1.53 2.17 1.17
19 konara 1.61 2.00 1.12
20 matebashii 2.96 2.75 1.35
21 matebashii 3.18 2.80 1.44
22 matebashii 3.08 2.73 1.42
23 matebashii 2.89 2.78 1.38
24 matebashii 3.68 2.83 1.51
25 matebashii 2.93 2.62 1.38
26 matebashii 2.30 2.50 1.26
27 matebashii 3.18 2.68 1.46
28 matebashii 3.13 2.76 1.40
29 matebashii 2.20 2.54 1.21
30 shirakashi 1.76 1.95 1.23
31 shirakashi 1.96 2.06 1.23
32 shirakashi 1.77 1.93 1.24
33 shirakashi 1.88 2.07 1.25
34 shirakashi 1.70 1.97 1.20
35 shirakashi 1.78 2.09 1.20
36 shirakashi 1.82 1.97 1.24
37 shirakashi 1.70 1.95 1.20
38 shirakashi 1.56 1.98 1.13
39 shirakashi 1.90 2.06 1.25
40 shirakashi 1.37 1.89 1.09
41 shirakashi 2.01 1.94 1.39
42 shirakashi 2.12 1.97 1.32
43 shirakashi 1.89 2.03 1.26
44 shirakashi 1.87 2.06 1.22
45 arakashi 1.68 1.89 1.23
46 arakashi 1.42 1.87 1.12
47 arakashi 1.54 1.82 1.15
48 arakashi 1.30 1.77 1.19
49 arakashi 1.53 1.81 1.18
50 arakashi 1.47 1.85 1.13
51 arakashi 1.64 1.89 1.26
52 arakashi 1.44 1.81 1.14
53 arakashi 1.36 1.87 1.09
54 arakashi 1.56 1.90 1.17
55 arakashi 1.49 1.82 1.17
56 arakashi 1.51 1.84 1.16
57 arakashi 1.41 1.88 1.12
58 arakashi 1.48 1.83 1.17
Jupyter Notebook を使用している場合、変数名を実行するだけで、その変数の中身が表示されます。この場合、Jupyter Notebook 独自の機能により、出力が見やすく整形されます。ただし、通常の Python 実行環境(たとえばターミナルや他のエディタ)では、同じような出力は得られません。
x
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 0 | kunugi | 5.55 | 2.27 | 1.89 |
| 1 | kunugi | 4.62 | 1.98 | 1.84 |
| 2 | kunugi | 5.05 | 2.08 | 1.90 |
| 3 | kunugi | 5.44 | 2.18 | 1.91 |
| 4 | kunugi | 5.60 | 2.20 | 1.93 |
| 5 | kunugi | 4.83 | 2.19 | 1.85 |
| 6 | kunugi | 5.55 | 2.16 | 2.00 |
| 7 | kunugi | 5.13 | 2.20 | 1.87 |
| 8 | kunugi | 6.03 | 2.26 | 2.01 |
| 9 | kunugi | 7.41 | 2.35 | 2.12 |
| 10 | konara | 1.60 | 2.11 | 1.10 |
| 11 | konara | 1.49 | 2.04 | 1.09 |
| 12 | konara | 1.74 | 2.30 | 1.17 |
| 13 | konara | 1.57 | 2.11 | 1.11 |
| 14 | konara | 1.88 | 2.33 | 1.11 |
| 15 | konara | 1.63 | 2.12 | 1.14 |
| 16 | konara | 1.45 | 2.06 | 1.09 |
| 17 | konara | 1.07 | 1.91 | 0.98 |
| 18 | konara | 1.53 | 2.17 | 1.17 |
| 19 | konara | 1.61 | 2.00 | 1.12 |
| 20 | matebashii | 2.96 | 2.75 | 1.35 |
| 21 | matebashii | 3.18 | 2.80 | 1.44 |
| 22 | matebashii | 3.08 | 2.73 | 1.42 |
| 23 | matebashii | 2.89 | 2.78 | 1.38 |
| 24 | matebashii | 3.68 | 2.83 | 1.51 |
| 25 | matebashii | 2.93 | 2.62 | 1.38 |
| 26 | matebashii | 2.30 | 2.50 | 1.26 |
| 27 | matebashii | 3.18 | 2.68 | 1.46 |
| 28 | matebashii | 3.13 | 2.76 | 1.40 |
| 29 | matebashii | 2.20 | 2.54 | 1.21 |
| 30 | shirakashi | 1.76 | 1.95 | 1.23 |
| 31 | shirakashi | 1.96 | 2.06 | 1.23 |
| 32 | shirakashi | 1.77 | 1.93 | 1.24 |
| 33 | shirakashi | 1.88 | 2.07 | 1.25 |
| 34 | shirakashi | 1.70 | 1.97 | 1.20 |
| 35 | shirakashi | 1.78 | 2.09 | 1.20 |
| 36 | shirakashi | 1.82 | 1.97 | 1.24 |
| 37 | shirakashi | 1.70 | 1.95 | 1.20 |
| 38 | shirakashi | 1.56 | 1.98 | 1.13 |
| 39 | shirakashi | 1.90 | 2.06 | 1.25 |
| 40 | shirakashi | 1.37 | 1.89 | 1.09 |
| 41 | shirakashi | 2.01 | 1.94 | 1.39 |
| 42 | shirakashi | 2.12 | 1.97 | 1.32 |
| 43 | shirakashi | 1.89 | 2.03 | 1.26 |
| 44 | shirakashi | 1.87 | 2.06 | 1.22 |
| 45 | arakashi | 1.68 | 1.89 | 1.23 |
| 46 | arakashi | 1.42 | 1.87 | 1.12 |
| 47 | arakashi | 1.54 | 1.82 | 1.15 |
| 48 | arakashi | 1.30 | 1.77 | 1.19 |
| 49 | arakashi | 1.53 | 1.81 | 1.18 |
| 50 | arakashi | 1.47 | 1.85 | 1.13 |
| 51 | arakashi | 1.64 | 1.89 | 1.26 |
| 52 | arakashi | 1.44 | 1.81 | 1.14 |
| 53 | arakashi | 1.36 | 1.87 | 1.09 |
| 54 | arakashi | 1.56 | 1.90 | 1.17 |
| 55 | arakashi | 1.49 | 1.82 | 1.17 |
| 56 | arakashi | 1.51 | 1.84 | 1.16 |
| 57 | arakashi | 1.41 | 1.88 | 1.12 |
| 58 | arakashi | 1.48 | 1.83 | 1.17 |
また、Jupyter Notebook 上では、たとえば次のように .style メソッドなどをデータに適用することで、数値データをわかりやすく可視化することができます。
x.style.background_gradient()
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 0 | kunugi | 5.550000 | 2.270000 | 1.890000 |
| 1 | kunugi | 4.620000 | 1.980000 | 1.840000 |
| 2 | kunugi | 5.050000 | 2.080000 | 1.900000 |
| 3 | kunugi | 5.440000 | 2.180000 | 1.910000 |
| 4 | kunugi | 5.600000 | 2.200000 | 1.930000 |
| 5 | kunugi | 4.830000 | 2.190000 | 1.850000 |
| 6 | kunugi | 5.550000 | 2.160000 | 2.000000 |
| 7 | kunugi | 5.130000 | 2.200000 | 1.870000 |
| 8 | kunugi | 6.030000 | 2.260000 | 2.010000 |
| 9 | kunugi | 7.410000 | 2.350000 | 2.120000 |
| 10 | konara | 1.600000 | 2.110000 | 1.100000 |
| 11 | konara | 1.490000 | 2.040000 | 1.090000 |
| 12 | konara | 1.740000 | 2.300000 | 1.170000 |
| 13 | konara | 1.570000 | 2.110000 | 1.110000 |
| 14 | konara | 1.880000 | 2.330000 | 1.110000 |
| 15 | konara | 1.630000 | 2.120000 | 1.140000 |
| 16 | konara | 1.450000 | 2.060000 | 1.090000 |
| 17 | konara | 1.070000 | 1.910000 | 0.980000 |
| 18 | konara | 1.530000 | 2.170000 | 1.170000 |
| 19 | konara | 1.610000 | 2.000000 | 1.120000 |
| 20 | matebashii | 2.960000 | 2.750000 | 1.350000 |
| 21 | matebashii | 3.180000 | 2.800000 | 1.440000 |
| 22 | matebashii | 3.080000 | 2.730000 | 1.420000 |
| 23 | matebashii | 2.890000 | 2.780000 | 1.380000 |
| 24 | matebashii | 3.680000 | 2.830000 | 1.510000 |
| 25 | matebashii | 2.930000 | 2.620000 | 1.380000 |
| 26 | matebashii | 2.300000 | 2.500000 | 1.260000 |
| 27 | matebashii | 3.180000 | 2.680000 | 1.460000 |
| 28 | matebashii | 3.130000 | 2.760000 | 1.400000 |
| 29 | matebashii | 2.200000 | 2.540000 | 1.210000 |
| 30 | shirakashi | 1.760000 | 1.950000 | 1.230000 |
| 31 | shirakashi | 1.960000 | 2.060000 | 1.230000 |
| 32 | shirakashi | 1.770000 | 1.930000 | 1.240000 |
| 33 | shirakashi | 1.880000 | 2.070000 | 1.250000 |
| 34 | shirakashi | 1.700000 | 1.970000 | 1.200000 |
| 35 | shirakashi | 1.780000 | 2.090000 | 1.200000 |
| 36 | shirakashi | 1.820000 | 1.970000 | 1.240000 |
| 37 | shirakashi | 1.700000 | 1.950000 | 1.200000 |
| 38 | shirakashi | 1.560000 | 1.980000 | 1.130000 |
| 39 | shirakashi | 1.900000 | 2.060000 | 1.250000 |
| 40 | shirakashi | 1.370000 | 1.890000 | 1.090000 |
| 41 | shirakashi | 2.010000 | 1.940000 | 1.390000 |
| 42 | shirakashi | 2.120000 | 1.970000 | 1.320000 |
| 43 | shirakashi | 1.890000 | 2.030000 | 1.260000 |
| 44 | shirakashi | 1.870000 | 2.060000 | 1.220000 |
| 45 | arakashi | 1.680000 | 1.890000 | 1.230000 |
| 46 | arakashi | 1.420000 | 1.870000 | 1.120000 |
| 47 | arakashi | 1.540000 | 1.820000 | 1.150000 |
| 48 | arakashi | 1.300000 | 1.770000 | 1.190000 |
| 49 | arakashi | 1.530000 | 1.810000 | 1.180000 |
| 50 | arakashi | 1.470000 | 1.850000 | 1.130000 |
| 51 | arakashi | 1.640000 | 1.890000 | 1.260000 |
| 52 | arakashi | 1.440000 | 1.810000 | 1.140000 |
| 53 | arakashi | 1.360000 | 1.870000 | 1.090000 |
| 54 | arakashi | 1.560000 | 1.900000 | 1.170000 |
| 55 | arakashi | 1.490000 | 1.820000 | 1.170000 |
| 56 | arakashi | 1.510000 | 1.840000 | 1.160000 |
| 57 | arakashi | 1.410000 | 1.880000 | 1.120000 |
| 58 | arakashi | 1.480000 | 1.830000 | 1.170000 |
x.style.bar()
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 0 | kunugi | 5.550000 | 2.270000 | 1.890000 |
| 1 | kunugi | 4.620000 | 1.980000 | 1.840000 |
| 2 | kunugi | 5.050000 | 2.080000 | 1.900000 |
| 3 | kunugi | 5.440000 | 2.180000 | 1.910000 |
| 4 | kunugi | 5.600000 | 2.200000 | 1.930000 |
| 5 | kunugi | 4.830000 | 2.190000 | 1.850000 |
| 6 | kunugi | 5.550000 | 2.160000 | 2.000000 |
| 7 | kunugi | 5.130000 | 2.200000 | 1.870000 |
| 8 | kunugi | 6.030000 | 2.260000 | 2.010000 |
| 9 | kunugi | 7.410000 | 2.350000 | 2.120000 |
| 10 | konara | 1.600000 | 2.110000 | 1.100000 |
| 11 | konara | 1.490000 | 2.040000 | 1.090000 |
| 12 | konara | 1.740000 | 2.300000 | 1.170000 |
| 13 | konara | 1.570000 | 2.110000 | 1.110000 |
| 14 | konara | 1.880000 | 2.330000 | 1.110000 |
| 15 | konara | 1.630000 | 2.120000 | 1.140000 |
| 16 | konara | 1.450000 | 2.060000 | 1.090000 |
| 17 | konara | 1.070000 | 1.910000 | 0.980000 |
| 18 | konara | 1.530000 | 2.170000 | 1.170000 |
| 19 | konara | 1.610000 | 2.000000 | 1.120000 |
| 20 | matebashii | 2.960000 | 2.750000 | 1.350000 |
| 21 | matebashii | 3.180000 | 2.800000 | 1.440000 |
| 22 | matebashii | 3.080000 | 2.730000 | 1.420000 |
| 23 | matebashii | 2.890000 | 2.780000 | 1.380000 |
| 24 | matebashii | 3.680000 | 2.830000 | 1.510000 |
| 25 | matebashii | 2.930000 | 2.620000 | 1.380000 |
| 26 | matebashii | 2.300000 | 2.500000 | 1.260000 |
| 27 | matebashii | 3.180000 | 2.680000 | 1.460000 |
| 28 | matebashii | 3.130000 | 2.760000 | 1.400000 |
| 29 | matebashii | 2.200000 | 2.540000 | 1.210000 |
| 30 | shirakashi | 1.760000 | 1.950000 | 1.230000 |
| 31 | shirakashi | 1.960000 | 2.060000 | 1.230000 |
| 32 | shirakashi | 1.770000 | 1.930000 | 1.240000 |
| 33 | shirakashi | 1.880000 | 2.070000 | 1.250000 |
| 34 | shirakashi | 1.700000 | 1.970000 | 1.200000 |
| 35 | shirakashi | 1.780000 | 2.090000 | 1.200000 |
| 36 | shirakashi | 1.820000 | 1.970000 | 1.240000 |
| 37 | shirakashi | 1.700000 | 1.950000 | 1.200000 |
| 38 | shirakashi | 1.560000 | 1.980000 | 1.130000 |
| 39 | shirakashi | 1.900000 | 2.060000 | 1.250000 |
| 40 | shirakashi | 1.370000 | 1.890000 | 1.090000 |
| 41 | shirakashi | 2.010000 | 1.940000 | 1.390000 |
| 42 | shirakashi | 2.120000 | 1.970000 | 1.320000 |
| 43 | shirakashi | 1.890000 | 2.030000 | 1.260000 |
| 44 | shirakashi | 1.870000 | 2.060000 | 1.220000 |
| 45 | arakashi | 1.680000 | 1.890000 | 1.230000 |
| 46 | arakashi | 1.420000 | 1.870000 | 1.120000 |
| 47 | arakashi | 1.540000 | 1.820000 | 1.150000 |
| 48 | arakashi | 1.300000 | 1.770000 | 1.190000 |
| 49 | arakashi | 1.530000 | 1.810000 | 1.180000 |
| 50 | arakashi | 1.470000 | 1.850000 | 1.130000 |
| 51 | arakashi | 1.640000 | 1.890000 | 1.260000 |
| 52 | arakashi | 1.440000 | 1.810000 | 1.140000 |
| 53 | arakashi | 1.360000 | 1.870000 | 1.090000 |
| 54 | arakashi | 1.560000 | 1.900000 | 1.170000 |
| 55 | arakashi | 1.490000 | 1.820000 | 1.170000 |
| 56 | arakashi | 1.510000 | 1.840000 | 1.160000 |
| 57 | arakashi | 1.410000 | 1.880000 | 1.120000 |
| 58 | arakashi | 1.480000 | 1.830000 | 1.170000 |
読み込んだデータ全体ではなく、たとえば最初の数行や最後の数行だけを表示したい場合には、head および tail メソッドを使用します。これらのメソッドは、標準では先頭または末尾の 5 行を表示しますが、引数 n を指定することで表示する行数を変更できます。また、head や tail の結果に対して、続けて style メソッドを適用することも可能です。
x.head()
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 0 | kunugi | 5.55 | 2.27 | 1.89 |
| 1 | kunugi | 4.62 | 1.98 | 1.84 |
| 2 | kunugi | 5.05 | 2.08 | 1.90 |
| 3 | kunugi | 5.44 | 2.18 | 1.91 |
| 4 | kunugi | 5.60 | 2.20 | 1.93 |
x.tail(n=8).style.bar()
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 51 | arakashi | 1.640000 | 1.890000 | 1.260000 |
| 52 | arakashi | 1.440000 | 1.810000 | 1.140000 |
| 53 | arakashi | 1.360000 | 1.870000 | 1.090000 |
| 54 | arakashi | 1.560000 | 1.900000 | 1.170000 |
| 55 | arakashi | 1.490000 | 1.820000 | 1.170000 |
| 56 | arakashi | 1.510000 | 1.840000 | 1.160000 |
| 57 | arakashi | 1.410000 | 1.880000 | 1.120000 |
| 58 | arakashi | 1.480000 | 1.830000 | 1.170000 |
5.1.3. データの行と列#
データフレームから特定の位置にある値を取り出すには、iloc または loc を使います。iloc は、行番号と列番号で指定するときに使用します。loc は、行名(インデックス)と列名で指定するときに使用します。
たとえば、データフレーム x の 1 行 3 列目のデータを取り出すには、iloc[0, 2] のように指定します。
x.iloc[0, 2]
np.float64(2.27)
なお、iloc および loc は、オブジェクトのインデクサー(indexer)と呼ばれ、添え字を使ってデータの位置やラベルを指定するための抽象的な操作手段です。インデクサーは、関数やメソッドとは異なるため、 () を使わずに [] を使って添え字を指定します。たとえば、iloc[0, 2] のように書くのが正しく、iloc(0, 2) のように書くとエラーになります。
5.1.3.1. 列の抽出#
特定の列だけを取り出す操作は、「ある列のすべての行を取り出す」ことと同じです。 たとえば、2 列目のデータをすべて取得したい場合は、iloc[:, 1] のように指定します。このとき、: は「すべての行」を意味し、1 は 2 番目の列を取り出すという指定になります。
x.iloc[:, 1]
0 5.55
1 4.62
2 5.05
3 5.44
4 5.60
5 4.83
6 5.55
7 5.13
8 6.03
9 7.41
10 1.60
11 1.49
12 1.74
13 1.57
14 1.88
15 1.63
16 1.45
17 1.07
18 1.53
19 1.61
20 2.96
21 3.18
22 3.08
23 2.89
24 3.68
25 2.93
26 2.30
27 3.18
28 3.13
29 2.20
30 1.76
31 1.96
32 1.77
33 1.88
34 1.70
35 1.78
36 1.82
37 1.70
38 1.56
39 1.90
40 1.37
41 2.01
42 2.12
43 1.89
44 1.87
45 1.68
46 1.42
47 1.54
48 1.30
49 1.53
50 1.47
51 1.64
52 1.44
53 1.36
54 1.56
55 1.49
56 1.51
57 1.41
58 1.48
Name: weight, dtype: float64
このように取り出した結果は、シリーズ(Series)というデータ型になります。シリーズは 1 列のデータを表しており、数学でいう列ベクトルのようなイメージです。基本的な扱い方はリストに似ていて、インデックスを指定して特定の位置の値を取得できます。さらに、シリーズの各要素には名前を付けることができ、名前が付いたシリーズでは、インデックスの番号だけでなく名前を使って値を取得することも可能です。
データフレームから複数の列を取り出す場合は、列番号をリストで指定します。
x.iloc[:, [1, 2, 3]]
| weight | height | diameter | |
|---|---|---|---|
| 0 | 5.55 | 2.27 | 1.89 |
| 1 | 4.62 | 1.98 | 1.84 |
| 2 | 5.05 | 2.08 | 1.90 |
| 3 | 5.44 | 2.18 | 1.91 |
| 4 | 5.60 | 2.20 | 1.93 |
| 5 | 4.83 | 2.19 | 1.85 |
| 6 | 5.55 | 2.16 | 2.00 |
| 7 | 5.13 | 2.20 | 1.87 |
| 8 | 6.03 | 2.26 | 2.01 |
| 9 | 7.41 | 2.35 | 2.12 |
| 10 | 1.60 | 2.11 | 1.10 |
| 11 | 1.49 | 2.04 | 1.09 |
| 12 | 1.74 | 2.30 | 1.17 |
| 13 | 1.57 | 2.11 | 1.11 |
| 14 | 1.88 | 2.33 | 1.11 |
| 15 | 1.63 | 2.12 | 1.14 |
| 16 | 1.45 | 2.06 | 1.09 |
| 17 | 1.07 | 1.91 | 0.98 |
| 18 | 1.53 | 2.17 | 1.17 |
| 19 | 1.61 | 2.00 | 1.12 |
| 20 | 2.96 | 2.75 | 1.35 |
| 21 | 3.18 | 2.80 | 1.44 |
| 22 | 3.08 | 2.73 | 1.42 |
| 23 | 2.89 | 2.78 | 1.38 |
| 24 | 3.68 | 2.83 | 1.51 |
| 25 | 2.93 | 2.62 | 1.38 |
| 26 | 2.30 | 2.50 | 1.26 |
| 27 | 3.18 | 2.68 | 1.46 |
| 28 | 3.13 | 2.76 | 1.40 |
| 29 | 2.20 | 2.54 | 1.21 |
| 30 | 1.76 | 1.95 | 1.23 |
| 31 | 1.96 | 2.06 | 1.23 |
| 32 | 1.77 | 1.93 | 1.24 |
| 33 | 1.88 | 2.07 | 1.25 |
| 34 | 1.70 | 1.97 | 1.20 |
| 35 | 1.78 | 2.09 | 1.20 |
| 36 | 1.82 | 1.97 | 1.24 |
| 37 | 1.70 | 1.95 | 1.20 |
| 38 | 1.56 | 1.98 | 1.13 |
| 39 | 1.90 | 2.06 | 1.25 |
| 40 | 1.37 | 1.89 | 1.09 |
| 41 | 2.01 | 1.94 | 1.39 |
| 42 | 2.12 | 1.97 | 1.32 |
| 43 | 1.89 | 2.03 | 1.26 |
| 44 | 1.87 | 2.06 | 1.22 |
| 45 | 1.68 | 1.89 | 1.23 |
| 46 | 1.42 | 1.87 | 1.12 |
| 47 | 1.54 | 1.82 | 1.15 |
| 48 | 1.30 | 1.77 | 1.19 |
| 49 | 1.53 | 1.81 | 1.18 |
| 50 | 1.47 | 1.85 | 1.13 |
| 51 | 1.64 | 1.89 | 1.26 |
| 52 | 1.44 | 1.81 | 1.14 |
| 53 | 1.36 | 1.87 | 1.09 |
| 54 | 1.56 | 1.90 | 1.17 |
| 55 | 1.49 | 1.82 | 1.17 |
| 56 | 1.51 | 1.84 | 1.16 |
| 57 | 1.41 | 1.88 | 1.12 |
| 58 | 1.48 | 1.83 | 1.17 |
次に、loc を使って行や列を抽出する方法を見ていきます。loc は、行名や列名を指定してデータを取り出すときに使用します。
たとえば、データフレーム x から weight 列を取り出したい場合は、次のように実行します。
x.loc[:, 'weight']
0 5.55
1 4.62
2 5.05
3 5.44
4 5.60
5 4.83
6 5.55
7 5.13
8 6.03
9 7.41
10 1.60
11 1.49
12 1.74
13 1.57
14 1.88
15 1.63
16 1.45
17 1.07
18 1.53
19 1.61
20 2.96
21 3.18
22 3.08
23 2.89
24 3.68
25 2.93
26 2.30
27 3.18
28 3.13
29 2.20
30 1.76
31 1.96
32 1.77
33 1.88
34 1.70
35 1.78
36 1.82
37 1.70
38 1.56
39 1.90
40 1.37
41 2.01
42 2.12
43 1.89
44 1.87
45 1.68
46 1.42
47 1.54
48 1.30
49 1.53
50 1.47
51 1.64
52 1.44
53 1.36
54 1.56
55 1.49
56 1.51
57 1.41
58 1.48
Name: weight, dtype: float64
複数の列を取り出す場合は、対象となる列名をリストとして与えます。
x.loc[:, ['height', 'diameter']]
| height | diameter | |
|---|---|---|
| 0 | 2.27 | 1.89 |
| 1 | 1.98 | 1.84 |
| 2 | 2.08 | 1.90 |
| 3 | 2.18 | 1.91 |
| 4 | 2.20 | 1.93 |
| 5 | 2.19 | 1.85 |
| 6 | 2.16 | 2.00 |
| 7 | 2.20 | 1.87 |
| 8 | 2.26 | 2.01 |
| 9 | 2.35 | 2.12 |
| 10 | 2.11 | 1.10 |
| 11 | 2.04 | 1.09 |
| 12 | 2.30 | 1.17 |
| 13 | 2.11 | 1.11 |
| 14 | 2.33 | 1.11 |
| 15 | 2.12 | 1.14 |
| 16 | 2.06 | 1.09 |
| 17 | 1.91 | 0.98 |
| 18 | 2.17 | 1.17 |
| 19 | 2.00 | 1.12 |
| 20 | 2.75 | 1.35 |
| 21 | 2.80 | 1.44 |
| 22 | 2.73 | 1.42 |
| 23 | 2.78 | 1.38 |
| 24 | 2.83 | 1.51 |
| 25 | 2.62 | 1.38 |
| 26 | 2.50 | 1.26 |
| 27 | 2.68 | 1.46 |
| 28 | 2.76 | 1.40 |
| 29 | 2.54 | 1.21 |
| 30 | 1.95 | 1.23 |
| 31 | 2.06 | 1.23 |
| 32 | 1.93 | 1.24 |
| 33 | 2.07 | 1.25 |
| 34 | 1.97 | 1.20 |
| 35 | 2.09 | 1.20 |
| 36 | 1.97 | 1.24 |
| 37 | 1.95 | 1.20 |
| 38 | 1.98 | 1.13 |
| 39 | 2.06 | 1.25 |
| 40 | 1.89 | 1.09 |
| 41 | 1.94 | 1.39 |
| 42 | 1.97 | 1.32 |
| 43 | 2.03 | 1.26 |
| 44 | 2.06 | 1.22 |
| 45 | 1.89 | 1.23 |
| 46 | 1.87 | 1.12 |
| 47 | 1.82 | 1.15 |
| 48 | 1.77 | 1.19 |
| 49 | 1.81 | 1.18 |
| 50 | 1.85 | 1.13 |
| 51 | 1.89 | 1.26 |
| 52 | 1.81 | 1.14 |
| 53 | 1.87 | 1.09 |
| 54 | 1.90 | 1.17 |
| 55 | 1.82 | 1.17 |
| 56 | 1.84 | 1.16 |
| 57 | 1.88 | 1.12 |
| 58 | 1.83 | 1.17 |
なお、列の抽出するときに、loc や iloc を使わなくても、列名を使って辞書のような記法でも取り出すことができます。たとえば、x['tree'] とするだけで、データフレーム x から tree 列を取り出すことができます。統計解析などでは列単位での処理が多く、このような簡潔な記法を使うことで、コードがより読みやすく、効率的になります。
x['tree']
0 kunugi
1 kunugi
2 kunugi
3 kunugi
4 kunugi
5 kunugi
6 kunugi
7 kunugi
8 kunugi
9 kunugi
10 konara
11 konara
12 konara
13 konara
14 konara
15 konara
16 konara
17 konara
18 konara
19 konara
20 matebashii
21 matebashii
22 matebashii
23 matebashii
24 matebashii
25 matebashii
26 matebashii
27 matebashii
28 matebashii
29 matebashii
30 shirakashi
31 shirakashi
32 shirakashi
33 shirakashi
34 shirakashi
35 shirakashi
36 shirakashi
37 shirakashi
38 shirakashi
39 shirakashi
40 shirakashi
41 shirakashi
42 shirakashi
43 shirakashi
44 shirakashi
45 arakashi
46 arakashi
47 arakashi
48 arakashi
49 arakashi
50 arakashi
51 arakashi
52 arakashi
53 arakashi
54 arakashi
55 arakashi
56 arakashi
57 arakashi
58 arakashi
Name: tree, dtype: object
5.1.3.2. 行の抽出#
データフレームから特定の行を取り出す場合も、基本的には iloc または loc を使います。列を取り出すときと同様に、行番号や行名を指定して抽出します。
x.iloc[0, :]
tree kunugi
weight 5.55
height 2.27
diameter 1.89
Name: 0, dtype: object
x.loc[0:4, :]
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 0 | kunugi | 5.55 | 2.27 | 1.89 |
| 1 | kunugi | 4.62 | 1.98 | 1.84 |
| 2 | kunugi | 5.05 | 2.08 | 1.90 |
| 3 | kunugi | 5.44 | 2.18 | 1.91 |
| 4 | kunugi | 5.60 | 2.20 | 1.93 |
条件を指定して特定の行を抽出することもできます。たとえば、「重さ(weight)」が 4.0g 以上のデータだけを取り出したい場合、まず条件に合致するかどうかを示す論理インデックスを作成し、それを使ってフィルタリングします。論理インデックスとは、各値が True または False となっているリストや、それと同等のシリーズや配列[1]のことを指します。
is_ge_4 = (x.loc[:, 'weight'] >= 4.0)
is_ge_4
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 False
18 False
19 False
20 False
21 False
22 False
23 False
24 False
25 False
26 False
27 False
28 False
29 False
30 False
31 False
32 False
33 False
34 False
35 False
36 False
37 False
38 False
39 False
40 False
41 False
42 False
43 False
44 False
45 False
46 False
47 False
48 False
49 False
50 False
51 False
52 False
53 False
54 False
55 False
56 False
57 False
58 False
Name: weight, dtype: bool
heavy_acorns = x.loc[is_ge_4, :]
heavy_acorns
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 0 | kunugi | 5.55 | 2.27 | 1.89 |
| 1 | kunugi | 4.62 | 1.98 | 1.84 |
| 2 | kunugi | 5.05 | 2.08 | 1.90 |
| 3 | kunugi | 5.44 | 2.18 | 1.91 |
| 4 | kunugi | 5.60 | 2.20 | 1.93 |
| 5 | kunugi | 4.83 | 2.19 | 1.85 |
| 6 | kunugi | 5.55 | 2.16 | 2.00 |
| 7 | kunugi | 5.13 | 2.20 | 1.87 |
| 8 | kunugi | 6.03 | 2.26 | 2.01 |
| 9 | kunugi | 7.41 | 2.35 | 2.12 |
論理インデックスは、数値の比較だけでなく、文字列の比較でも作成できます。例えば、アラカシ(arakashi)のデータだけを抽出したい場合は次のように実行します。
arakashi = x.loc[x.loc[:, 'tree'] == 'arakashi', :]
arakashi
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 45 | arakashi | 1.68 | 1.89 | 1.23 |
| 46 | arakashi | 1.42 | 1.87 | 1.12 |
| 47 | arakashi | 1.54 | 1.82 | 1.15 |
| 48 | arakashi | 1.30 | 1.77 | 1.19 |
| 49 | arakashi | 1.53 | 1.81 | 1.18 |
| 50 | arakashi | 1.47 | 1.85 | 1.13 |
| 51 | arakashi | 1.64 | 1.89 | 1.26 |
| 52 | arakashi | 1.44 | 1.81 | 1.14 |
| 53 | arakashi | 1.36 | 1.87 | 1.09 |
| 54 | arakashi | 1.56 | 1.90 | 1.17 |
| 55 | arakashi | 1.49 | 1.82 | 1.17 |
| 56 | arakashi | 1.51 | 1.84 | 1.16 |
| 57 | arakashi | 1.41 | 1.88 | 1.12 |
| 58 | arakashi | 1.48 | 1.83 | 1.17 |
次のように簡潔に記述することもできます。
arakashi = x.loc[x['tree'] == 'arakashi', :]
arakashi
| tree | weight | height | diameter | |
|---|---|---|---|---|
| 45 | arakashi | 1.68 | 1.89 | 1.23 |
| 46 | arakashi | 1.42 | 1.87 | 1.12 |
| 47 | arakashi | 1.54 | 1.82 | 1.15 |
| 48 | arakashi | 1.30 | 1.77 | 1.19 |
| 49 | arakashi | 1.53 | 1.81 | 1.18 |
| 50 | arakashi | 1.47 | 1.85 | 1.13 |
| 51 | arakashi | 1.64 | 1.89 | 1.26 |
| 52 | arakashi | 1.44 | 1.81 | 1.14 |
| 53 | arakashi | 1.36 | 1.87 | 1.09 |
| 54 | arakashi | 1.56 | 1.90 | 1.17 |
| 55 | arakashi | 1.49 | 1.82 | 1.17 |
| 56 | arakashi | 1.51 | 1.84 | 1.16 |
| 57 | arakashi | 1.41 | 1.88 | 1.12 |
| 58 | arakashi | 1.48 | 1.83 | 1.17 |
5.1.4. データの集計#
データフレームの各列について、欠損値を除いた後の平均値、分散、サンプル数(件数)などの概要統計量を確認するには、describe メソッドを利用します。このメソッドを使用すると、数値型の列すべてに対して、基本的な統計情報が自動的に計算されます。
x.describe()
| weight | height | diameter | |
|---|---|---|---|
| count | 59.000000 | 59.000000 | 59.000000 |
| mean | 2.512373 | 2.131864 | 1.337966 |
| std | 1.508329 | 0.296505 | 0.291889 |
| min | 1.070000 | 1.770000 | 0.980000 |
| 25% | 1.535000 | 1.905000 | 1.145000 |
| 50% | 1.780000 | 2.060000 | 1.230000 |
| 75% | 3.020000 | 2.230000 | 1.395000 |
| max | 7.410000 | 2.830000 | 2.120000 |
また、特定の列だけに対して概要統計量を計算したい場合は、まずその列を取り出し、その後で describe メソッドを適用します。
x.loc[:, 'weight'].describe()
count 59.000000
mean 2.512373
std 1.508329
min 1.070000
25% 1.535000
50% 1.780000
75% 3.020000
max 7.410000
Name: weight, dtype: float64
概要統計量だけでなく、基本的な統計量を個別に計算することもできます。例えば、平均や分散は次のように計算できます。いくつかの例を次に示します。
x.loc[:, 'weight'].mean()
np.float64(2.5123728813559314)
x.loc[x['tree'] == 'kunugi', 'weight'].mean()
np.float64(5.520999999999999)
x.loc[x['tree'] == 'kunugi', ['weight', 'height']].var()
weight 0.611766
height 0.010468
dtype: float64
このように、データフレームやシリーズの後ろに関数名を付けて実行すると、それぞれの列や要素に対してその関数が適用されます。ここで使われている mean や var は、データフレームやシリーズ専用に定義された関数で、これをメソッドと呼びます。メソッドは、特定のデータ型に対してのみ使える関数であり、他の型には使えません。たとえば、リストに対して mean を実行しようとすると、次のようなエラーが表示されます。
y = [1, 2, 3]
y.mean()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[29], line 2
1 y = [1, 2, 3]
----> 2 y.mean()
AttributeError: 'list' object has no attribute 'mean'
AttributeError が表示された場合は、そのメソッドが使えるデータ型になっているかどうかを確認してみてください。データフレームのつもりで使っていたのに、実はリストだったという思い込みが原因なことがよくあります。Python は察してくれません。ないものはないと言います。しかも、けっこう冷たく。
次に、データに含まれる木の種類の数を調べてみましょう。データフレーム x の tree 列には、どんぐりを採取した木の種類が記録されています。このデータに何種類の木が含まれているのかを調べるには、unique メソッドを使います。
x['tree'].unique()
array(['kunugi', 'konara', 'matebashii', 'shirakashi', 'arakashi'],
dtype=object)
このメソッドを使うと、tree 列に登場するユニークな値(重複のない値)が配列として表示されます。また、unique の代わりに value_counts メソッドを使うと、ユニークな値とその出現頻度を簡単に確認できます。結果はシリーズ型で返され、木の種類ごとのデータ数がわかります。
x['tree'].value_counts()
tree
shirakashi 15
arakashi 14
kunugi 10
konara 10
matebashii 10
Name: count, dtype: int64
Pandas には、簡単なグラフを描くためのメソッドも用意されています。たとえば、データフレームに対して hist メソッドを使うと、すべての列に対してヒストグラムが一度に描かれます。データがどのような分布になっているかを手軽に確認できます。なお、hist メソッドは内部で Matplotlib ライブラリを使っています。そのため、事前に Matplotlib をインポートしておく必要があります。
import matplotlib
x.hist()
array([[<Axes: title={'center': 'weight'}>,
<Axes: title={'center': 'height'}>],
[<Axes: title={'center': 'diameter'}>, <Axes: >]], dtype=object)
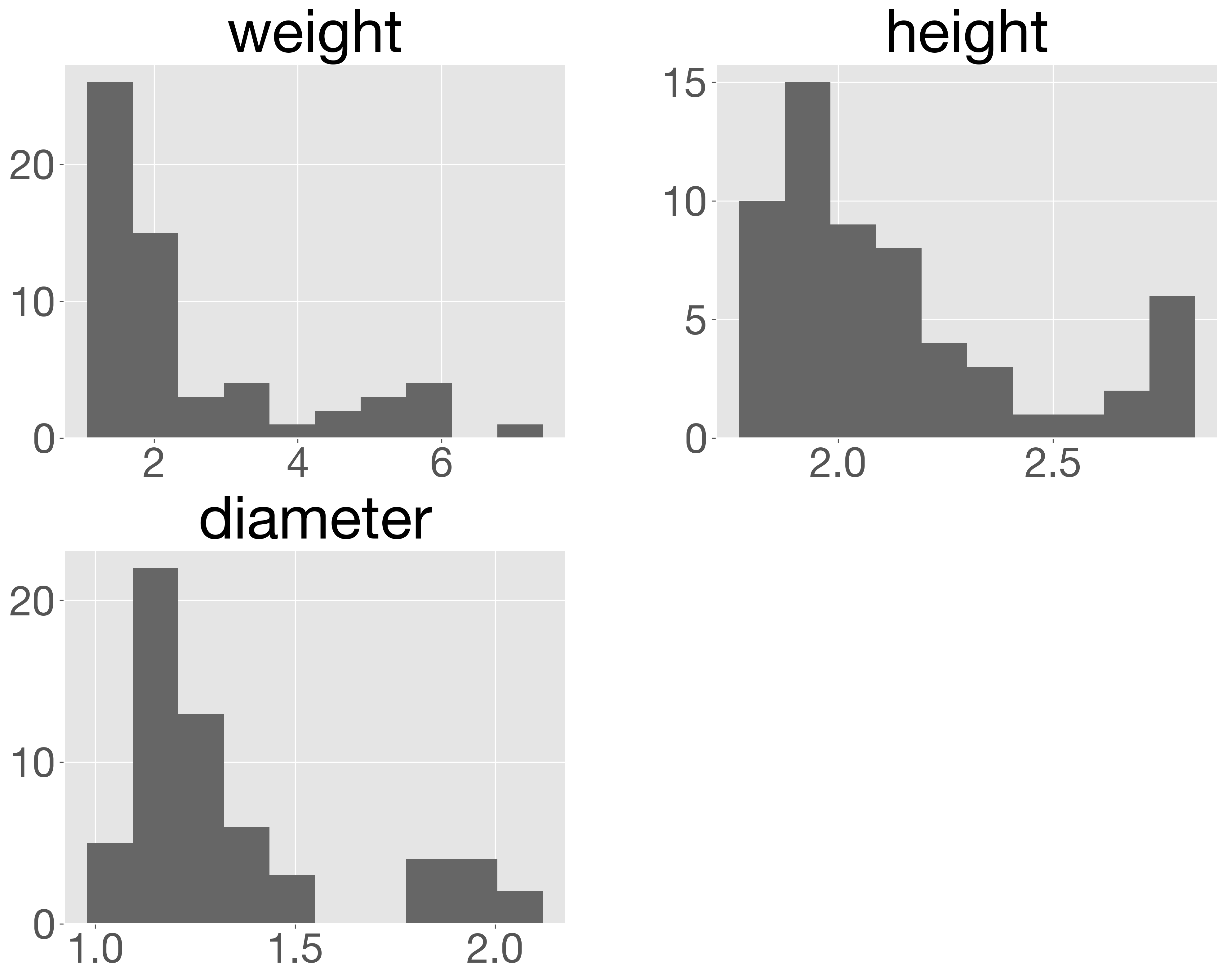
Pandas の可視化機能は、データの大まかな傾向や分布を素早く把握するのに便利です。しかし、細かい調整にはあまり向いていません。より柔軟で美しいグラフを作成したい場合は、Matplotlib や Seaborn といった外部ライブラリを利用するのがおすすめです。
練習問題 PD-1
acorns.csv データを読み込み、クヌギ(kunugi)のどんぐりについて、重さ(weight)、高さ(height)、直径(diameter)の平均値をそれぞれ求めなさい。
練習問題 PD-2
acorns.csv データを読み込み、平均重量が最も重いどんぐりの種類を調べなさい。
練習問題 PD-3
acorns.csv データを読み込み、アラカシ(arakashi)の採種地点(location)を調べ、それぞれの地点ごとに平均重量を求めなさい。
練習問題 PD-4
acorns.csv データを読み込み、クヌギ(kunugi)のどんぐりの重さ(weight)が 4.0g 以上のデータだけを抽出し、その件数を求めなさい。
合ってそうに見える出力がいちばん怖い。特に締切前は。